Anatomy of a great SKILL.md
A great SKILL.md does three things at once: it tells the LLM when to load itself (the description), it teaches the LLM how to perform the task (the body), and it gives the LLM enough examples to handle edge cases without escalating to the user. If any of these three are missing, the skill either does not get loaded (description failure), does the wrong thing (body failure), or asks the user too many clarifying questions (examples failure).
The frontmatter fields
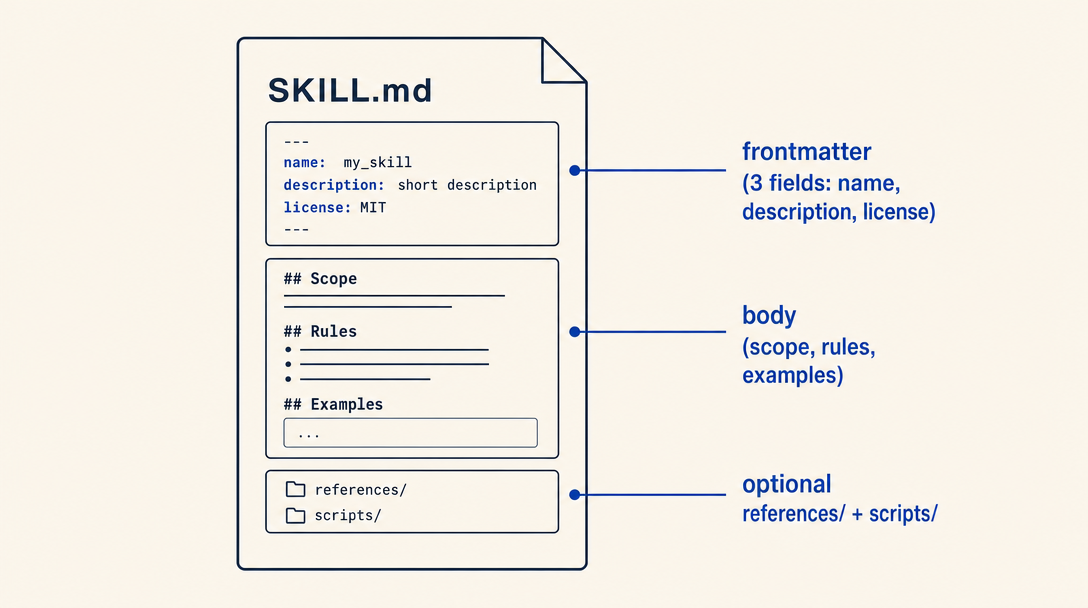
---
name: id-validator
description: Validate national ID numbers (such as the Israeli תעודת זהות) using a Luhn-style check-digit algorithm. Use when a user pastes a 9-digit ID and asks "is this valid", or when generating sample IDs for testing. Do NOT use for credit card numbers, EAN barcodes, or international passport numbers.
license: MIT
---
namemust be kebab-case, must match the folder name exactly, and is the slug the LLM uses to identify the skill internally. Pick something specific:id-validator, notid-tools. Required by the spec.descriptionis the single most important field in your skill. In hosts that use description-based routing (Claude Code's skill discovery is the canonical case), the LLM reads primarily this field to decide whether to load the skill into context. In other hosts the user explicitly picks the skill from a list, but the description is still what the LLM sees first. Treat it as both marketing copy and a routing specification. Required by the spec.licenseis typicallyMIT. The Anthropic upstream spec treats license as conventional rather than strictly required, but most ecosystem tooling expects it. Include it.
The description is the routing input
In hosts that auto-discover skills by description (Claude Code is the canonical case), the LLM scans the descriptions of available skills to decide which (if any) to load. It does NOT read the body. It does NOT read the references/. It reads only the description. In hosts where the user explicitly picks a skill from a list (Claude Desktop, some Cursor flows), the description is still the user-facing summary that determines whether they click. Either way, the description has to:
- Name the task clearly (in both languages of the term, if there's a non-English name)
- Trigger on the natural-language patterns a user would actually use
- Exclude cases that look similar but require a different skill
The "Use when..." and "Do NOT use for..." patterns make this concrete:
"Validate national ID numbers (such as the Israeli תעודת זהות) using a Luhn-style check-digit algorithm. Use when a user pastes a 9-digit ID and asks 'is this valid', or when generating sample IDs for testing. Do NOT use for credit card numbers, EAN barcodes, or international passport numbers."
The "Do NOT" clause is critical. Without it, the LLM might load this skill when the user asks about a credit-card check digit, then try to apply the Luhn variant tuned for 9-digit national IDs and fail confusingly. With the "Do NOT" clause, the LLM correctly routes elsewhere.
Body structure: scope, rules, examples, anti-patterns
The body is what the LLM reads after deciding to load the skill. It needs four sections, in roughly this order:
- Scope (one paragraph): what exactly this skill covers, restated more precisely than the description allowed.
- Decision rules (the meat): the if-then logic the LLM should apply. Use bulleted lists, decision trees, or worked examples. Avoid prose.
- Worked examples (mandatory): show the input, the reasoning, and the output. Cover the typical case and at least one edge case. Without worked examples, the LLM hallucinates the boundary behavior.
- Anti-patterns (recommended): tell the LLM what NOT to do, even if it sounds tempting. Anti-patterns prevent failure modes that would otherwise look correct.
Body length costs tokens
Everything in the body loads into context every time the skill routes. A 4000-word body costs roughly 5K-6K tokens per triggering turn in English (Hebrew is heavier). For a skill that triggers often, this becomes real money over a month.
The optimization rule: keep the body short and decision-focused. Push long lookup tables, templates, and detailed prose to references/, which the LLM reads on demand only when its reasoning calls for it. Chapter 4 expands on this split.
Study example: read a small focused skill
The fastest way to internalize this is to read one. Find a small skill (~150 lines) with a clear scope, a deterministic algorithm in scripts/, and concrete worked examples. Public catalogs typically let you browse by install count, which surfaces well-designed reference skills quickly. Reading one end to end is faster than any further description here can be.
The most common mistake in Chapter 2: writing a description that is too vague. "A skill for Israeli things" gets loaded for every Israeli-context conversation and does nothing useful for any of them. Pick ONE task. Name it specifically. Add the "Use when..." and "Do NOT use for..." patterns.
Want to keep reading?
Sign in to unlock the rest of the course and track your progress.